關鍵詞排名新聞
- 總結百度seo關鍵詞優化的3大技巧
- 深圳關鍵詞優化帶你了解外鏈形式對網站權重提升的作用
- 網站關鍵詞優化軟件分析和論述新站內容頁面收錄延遲的原因有哪些
- 深圳關鍵詞優化教你如何選擇優質而穩定的服務器
- 網站更換IP會不會對SEO優化有影響
- 如何利用網站標題優化獲得更多長尾關鍵詞排名
- 網站更換域名如何將影響降到最低
- 降低網站跳出率的辦法有哪些
- 關于網站收錄的核心問題如何解決
- 網站關鍵詞優化軟件教你怎么優化網站中的二級域名
- 網站關鍵詞優化軟件分享關于選擇域名和空間的小技巧
- seo更新文章要注意的事項有哪些
- 關于做網站seo時高指數的關鍵詞該如何優化
- 做好長尾關鍵詞是提升流量的最有效方法
- 如何分析關鍵詞優化難度
- 深圳關鍵詞優化軟件教你如何做好關鍵詞布局
- 網站關鍵詞優化怎樣討好搜索引擎
- 分析關鍵詞排名浮動的原因有哪些
- 深圳關鍵詞優化軟件淺談關鍵詞優化白帽與黑帽區別
- 網站文章關鍵詞優化有哪些技巧
- 如何評判網站關鍵詞優化是否成功
- 深圳搜索引擎關鍵詞優化淺談優化網站的詳細方法
- 深圳關鍵詞優化教你如何簡化標題提升關鍵詞
- 深圳關鍵詞優化需要注意些什么
- 淺談seo優化中有哪些常見的錯誤
百度排名優化之Baiduspider抓取過程中涉及的網絡協議
來源:http://m.91hf8.com/ 發布時間:2016年07月07日
剛才提到百度搜索引擎會設計復雜的抓取策略,其實搜索引擎與資源提供者之間存在相互依賴的關系,其中搜索引擎需要站長為其提供資源,否則搜索引擎就無法滿足用戶檢索需求;而站長需要通過搜索引擎將自己的 內容推廣出去獲取更多的受眾。spider抓取系統直接涉及互聯網資源提供者的利益,為了使搜素引擎與站長能夠達到雙贏,在抓取過程中雙方必須遵守一定的 規范,以便于雙方的數據處理及對接。這種過程中遵守的規范也就是日常中我們所說的一些網絡協議。
以下簡單列舉:
http協議:超文本傳輸協議,是互聯網上應用最為廣泛的一種網絡協議,客戶端和服務器端請求和應答的標準。客戶端一般情況是指終端用戶,服務器端即指網 站。終端用戶通過瀏覽器、蜘蛛等向服務器指定端口發送http請求。發送http請求會返回對應的httpheader信息,可以看到包括是否成功、服務 器類型、網頁最近更新時間等內容。
https協議:實際是加密版http,一種更加安全的數據傳輸協議。
UA屬性:UA即user-agent,是http協議中的一個屬性,代表了終端的身份,向服務器端表明我是誰來干嘛,進而服務器端可以根據不同的身份來做出不同的反饋結果。
robots協議:robots.txt是搜索引擎訪問一個網站時要訪問的第一個文件,用以來確定哪些是被允許抓取的哪些是被禁止抓取的。 robots.txt必須放在網站根目錄下,且文件名要小寫。詳細的robots.txt寫法可參考 http://www.robotstxt.org 。百度嚴格按照robots協議執行,另外,同樣支持網頁內容中添加的名為robots的meta標 簽,index、follow、nofollow等指令。





相關文章
- 百度排名優化之Baiduspider主要抓取策略類型2016年07月07日
- 百度排名優化關于索引量,你必須知道的事2016年07月07日
- 百度排名優化百度索引量工具常見問題2016年07月07日
- 百度排名優化如何定制百度索引量查看規則2016年07月07日
- 百度排名優化如何使用百度索引量工具2016年07月07日
 首頁
首頁
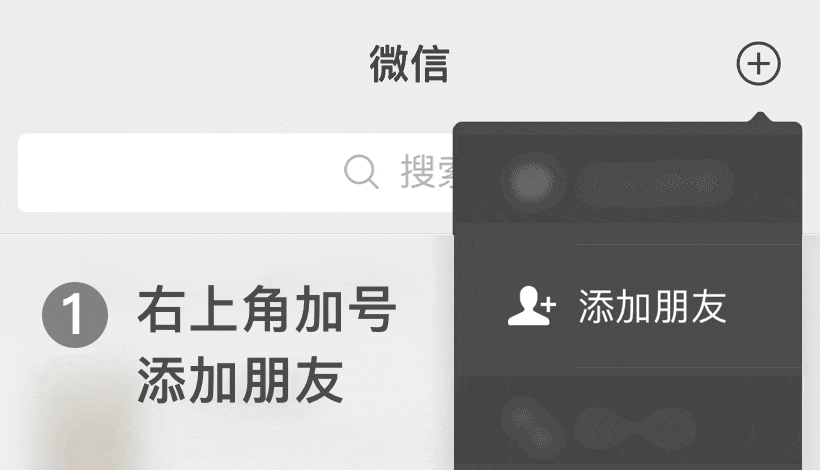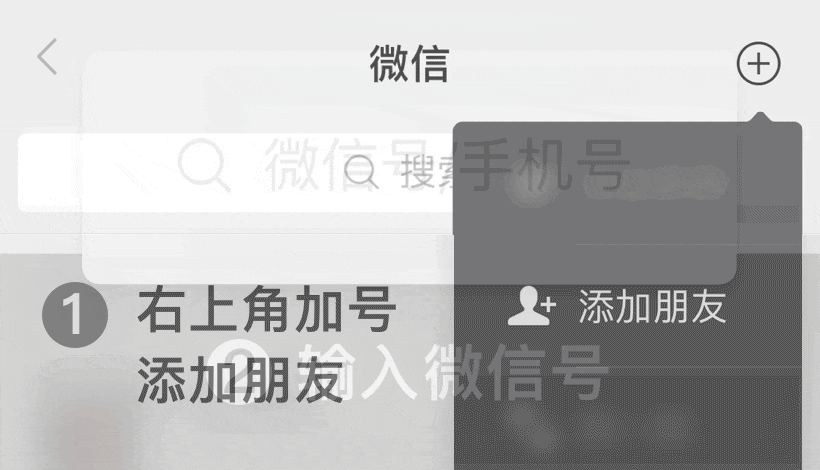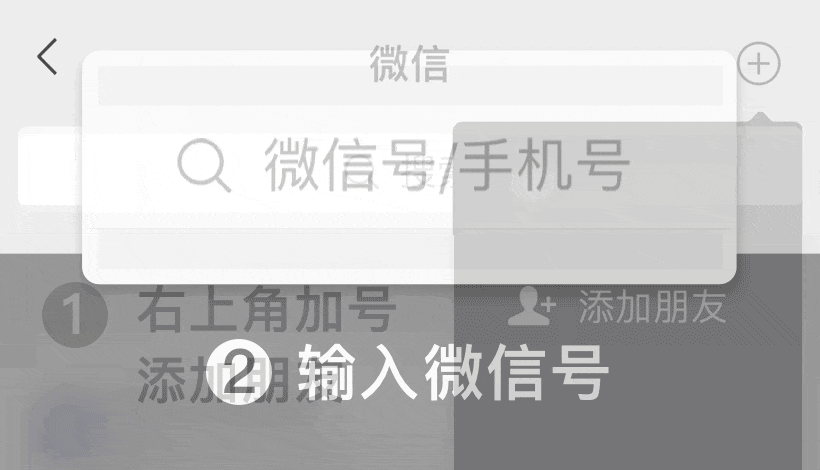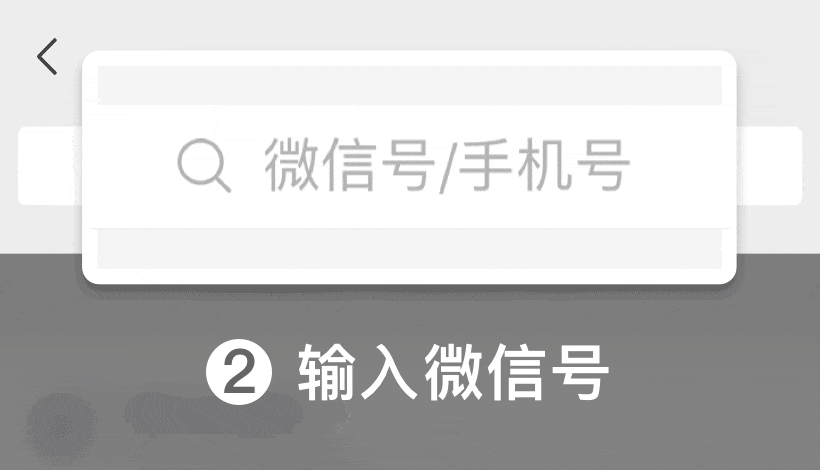
 添加微信
添加微信
 短信
短信
 電話咨詢
電話咨詢
 微信號:
微信號: